\"")
May 2015
Is my RDF engine the right one to retrieve my data ?
This document is intended for an audience starting or already working with Semantic Web technologies involving RDF Engines.
Once you imported RDF entities into your RDF store you can start developing your Web3 application using your pilot use case. RDF triples come out of your RDF store as requested and your pilot is performing. Your customer is enthusiastic and you get the order of building a scalable system hosting millions or billions of triples. Very soon you perceive that your RDF engine is probably consuming (too much) time and resources – and RDF material is not processed as you tested in the pilot. Key of this experience are the RDF representation and RDF engine used. In some cases you need just the retrieval of specific triples, in other logical connections, in another application even complexely explored knowledge. Then you probably start asking yourself the question: is the RDF engine in my RDF store always the right way to get to information? The answer depends on the use case you have for that RDF retrieval. I identified the following minimal abstracted use cases on which this post will be based.
- Use Case 1: Retrieving RDF triples using misspelled text
- Use Case 2: Retrieving RDF triples exploiting logical connections
- Use Case 3: Retrieving RDF triples involving huge graphs
Depending on the use case a different RDF engine (or suitable artifact) can be advantageously taken into consideration. Figure 1 depicts a metaphor of the use cases with the “Chronos” statue with three heads, one for each of the use cases. In this post I refer to both “RDF store” and “RDF engine” as parts of the same system – an RDF Management System (RDFMS).

Figure 1: Statue of Chronos with three heads: man, bull, and a lion as a metaphor of different needs in retrieving the same RDF
You need to identify information held by a triple using a possibly misspelled text, out of one or more objects in your RDF material. The typical case is the autocomplete case, where the user searches for suggestions to his/her typing text into some searching text field inside the application. Another case is given by identifying concepts starting from a possibly misspelled text.
Figure 2: Autocomplete as the main example of retrieving using misspelled text
The application logic layer of a Semantic Web Application needs specific data starting from precisely defined entities or text. The task is here to deliver just the “right” information, not more, not less. Additionally logic needs inferences.
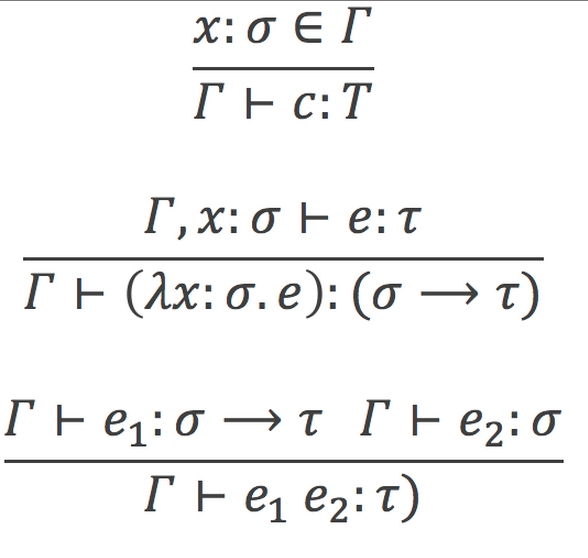
Figure 3: Inference rules in Lambda calculus as a metaphor for RDF inferences
Huge graphs (trillions of triples and more) should be traversed by algorithms possibly in parallel to solve NP-hard tasks like “shortest paths” algorithms to opportunely explore ways in the Knowledge Graph (artificial intelligence tasks).
Figure 4: Small portions of a huge graph
– Needs speed and results ranking
That is why you need for Use Case 1 a text engine capable of indexing and returning triples on the basis of mere (possibly) misspelled text, like SOLR™ or ElasticSearch™. Provided every triple is indexed at sub token level, it will deliver a ranked list of triples corresponding to your input text! Some RDF storage systems offer a kind of indexing in the triple namespace thus getting closer to this functionality. None of them offers nowadays support to potentially misspelled query texts.
– Needs logical soundness with (RDFS or type) inference, finding every connection in the graph and infer intensional truth.
That is why you need for Use Case 2 an RDFMS based on classical retrieval, like Virtuoso™ or GraphDB™ (/VIRTUOSO/,/GRAPHDB/) capable of sequentially accessing, inferring and delivering the “sound” data for you. Most of these RDF storage systems implements the SAIL interface /SAIL/ and organize their data sequentially with an own index on a BTree.
– Needs navigational speed and parallelism.
That is why you need for Use Case 3 a real Graph Engine like Neo4J™ or MapGraph™ (/NEO4J/, /MAPGRAPH/) or any Graph Store implementing the blueprints SAIL /BLUESAIL/ which treats a knowledge graph natively, i.e. using graph traversal technologies instead of database technology. Parallel navigational tasks can deliver – upon sufficient hardware – high speed together with results. Unfortunately: no inference!
Several applications around Semantic Web offer per se a search field to find specific data in the own or outer Linked Data RDF application space. All three approaches can be implemented for one application using the same RDF data with different RDF engines, based on one single RDF store, like figure 5 shows. Having several RDF Engines at work it is crucial that RDF data be updated synchronously between each of the connected RDF Storage systems.
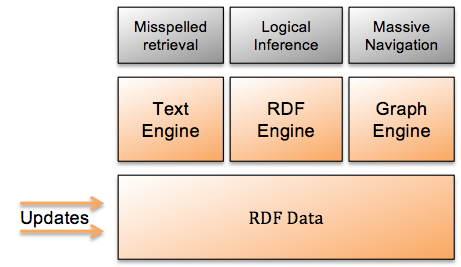
Figure 5: Three different RDF engines can co-exist in one system
Having several RDF engines serving your application, help overcome the limits of a single one.
This post illustrated several ways to exploit RDF information depending on general use cases and using different ways of retrieving RDF Data. Three main use cases were sketched and three different kinds of RDF engines are suggested. Running several RDF engines in parallel is a good idea as long as an update of the underlying RDF material is assured. Every RDF engine has own strengths. Having multiple RDF storage and retrieval system at your side will not reduce but enhance the overall performance!
| /BLAZE15/ | Blazegraph – http://www.systap.com/blazegraph |
| /BLUESAIL/ | Blueprints SAIL interface – https://github.com/tinkerpop/blueprints/wiki/Sail-Implementation |
| /DBPEDIA14/ | DBPedia – http://wiki.dbpedia.org/Downloads2014 |
| /ESCTL2012/ | An E-Science Tool for Managing Information in the Web of Documents and the Web of Knowledge (en) [J. Belmonte, E. Blumer, F. Ricci, R. Schneider] – IMCW 2012, Ankara, (T) |
| /ELD2015/ | Entity Linker Demonstrator – http://semweb.ch/leistungen/rdfservices/en-entitylinking |
| /GRAPHDB/ | RDF Store – http://www.ontotext.com/products/ontotext-graphdb/ |
| /RDF/ | Resource Description Framework – http://www.w3.org/RDF |
| /MAPGRAPH/ | Resource Description MapGraph – http://mapgraph.io/ |
| /NEO4J/ | RDF Graph Store – http://neo4j.com/ |
| /RDFSE2013/ | Linking Search Results, Bibliographical Ontologies and Linked Open Data Resources (en) [F. Ricci, Javier Belmonte, Eliane Blumer, René Schneider] – MTSR, Thessaloniki (G) November 2013 |
| /SAIL/ | SAIL interface – http://rdf4j.org/sesame/2.7/docs/users.docbook?view |
| /SKOS/ | Simple Knowledge Organization System – http://en.wikipedia.org/wiki/Simple_Knowledge_Organization_System |
| /SPARQL/ | W3C SPARQL 1.1 recommendation – http://www.w3.org/TR/sparql11-query/ |
| /SWEL15B/ | Extraction of Semantic Correlations between Entities – http://semweb.ch/de-blog/201504-extractionofsemrelships/ |
| /VIRTUOSO/ | RDF Store – https://www.w3.org/2001/sw/wiki/OpenLink_Virtuoso |