\"")
March 2015
Discovering Entities in Knowledge Graphs
This blog is intended for an audience working with computer text assistance using or finding details of linked entities in a knowledge graph starting from a natural language text.
Nowadays we are literally overflown with notes, emails, documents, and news. The challenge often is to remain smiling while keeping the balance between our working duties and the information overflow, summarizing – or even better: reading already summarized – “essentials” on topics concerning our personal or enterprise focus. Since our “domestic robot” is not always able to prepare for us the needed pieces of information – most of us have to do it nowadays still by themselves. Couldn’t we be positively surprised by having at reading time automatically all the entities that piece of news is speaking about on a silver tablet completed by their definitions, details and related entities to be browsed (on demand)! That is what “Entity Linking” stands for: Recognizing rigorous and detailed Entities of a knowledge graph from the piece of information, which is just entering my horizon – a natural language text.
Using large Knowledge Graphs with millions or billions of entities like encyclopedias or large ontologies does not necessarily imply one already knows all the entities. Imagine a piece of news is entering your consciousness horizon where “important” persons and/or “important” firms are involved acting on the subjects of your interest, some of which you do not (yet) know…! Having a compact detailed representation of each entity the piece of news (but even a larger document) is describing, orientates quickly the understanding. “New” persons, firms or localities will be visible to you as discovered entities together with their details and related information.
With a simple adequate methodology – e.g. tagging – each linked entity can be highlighted directly in the piece of news you are reading as a tagged word of this text, like the example in figure 1 shows. In case you need to know more about some new “discovered” entities, you are probably delighted to recognize that any discovery of further related entities starting from one linked graph entity can be pursued in as fast as a mouse hover: the advantage of using a knowledge graph is the direct reachability of every related resource or property on each entity.

Figure 1 – tagged (linked) entities from a piece of news allow direct access to other entities.
For a computer system the main challenge is recognizing the “right” entity in the graph.
The following issues arise:
Linguistic issues – Sentence parsing, recognizing phrase components.
Semantic issues – Disambiguation (irony and metaphors vs. ID’s and labels in the graph).
Speed – Recognition should not take more than the time a human being takes for reading.
The recognition of phrase components is nowadays well solved; several tools are already on the market. Universities deliver excellent technology for phrase tokenization for international used natural languages like English, German, French, which work … in seconds. One of the central challenges in Entity Linking remains disambiguation. A natural language – or better: the use of a natural language like English – is often characterized by the use of overloaded terms (speak: ambiguous terms) having more than one meaning and hence more than one entity to be linked in the knowledge graph. These circumstances present multiple challenges:
1) The knowledge graph representation of an entity is realized via /RDF/ models using an ID and one or more labels for that entity.
2) The writer intention could contain irony, satire or metaphors thus “falsifying” a lexemes based syntactical linking of terms.
3) The term is ambiguous per se in that language.
The RDF representation of entities in knowledge graphs foresees the use of an ID, which should be unique and expressive at the same time. This reflects the need for “orthogonality” of descriptions in computer science (one entity is described at one and only one place in the data space) together with the ambition of recognizing the entity through its ID even as the underlying language evolves in time and terms. The latter circumstance brings some salt to the soup: “broadcast” meant in the past “sowing seeds with a sweeping movement of the hand” while today it is more “the way the BBC spreads the news”. If this change should be reflected inside an RDF resource in a knowledge graph we would have either to change its ID and all the related resources inside the graph, including its label(s). Then we would get an entity with several textual descriptions, one of which is the preferred one, according to the /SKOS/ recommendation. A (human) writer which using irony, satire or metaphors puts some further salt on the soup this since the “linking machine” should then know all the possible meanings linked to an ironically or metaphorically meant term, rank them with respect to the case and disambiguate the currently processed term. Further analysis is here additionally needed to rank the possible uses of ironical intended terms trying all sentences and rank them with a suitable metrics to match the case.
Irony, satire or metaphors are solved by natural language answering systems like /Watson11/ running on computer clusters and demanding a high degree of resources. Because we do not always know how deep to disambiguate, this process might need a high degree of resources ranging up to several machines, which should be present / retrievable at entity linking time. A further problem of Entity Linking resides in the growing habit of using mixed languages inside one sentence like in the case of German with embedded English technical words. This slows down recognition time because all the possible language combinations have to be tested to make the linking reliable. In the remaining circumstances making – 80% of the cases – the process of Entity Linking implements a great help describing most entities involved in the text. Another very important issue is characterized by the update sources. How does all that information comes in – reliably – in my knowledge graph? Since what is not in the graph cannot be linked. A series of crawlers taking/filtering daily updates from “reliable” sources should provide the basis on which linking algorithms will find the (new) entities out of a natural language text.
In /ELd2015/ I proposed a very simple approach to Entity Linking delivering links in reading time. This approach is based on the DBPedia2014 dataset /DBP2014/ and uses an NLP tool to tokenize sentences as well as a current state-of-the art RDF store to store/retrieve knowledge graph entities through SPARQL. Each complex compound term is linked with the corresponding entity and the detail information is shown inside a tab below the text analyzed. Hovering a linked entity shows its detail information. A navigable graphical representation of the linked entity with its related/connected entities in the encyclopedia allows for quick visiting experiences – figure 2. The user gathers information out of related entities with one single mouse click, repeating this visual navigational discovering behavior until he/she reached the information need. There is no automatic disambiguation: where a disambiguation is needed, this is presented to the user like an entity with related entities, where the user can disambiguate quickly navigational by choosing in the graphical representation the right entity out of the connected entities inside the encyclopedia. Figure 3 shows the outcome of the linker for a piece of news of 147 words.
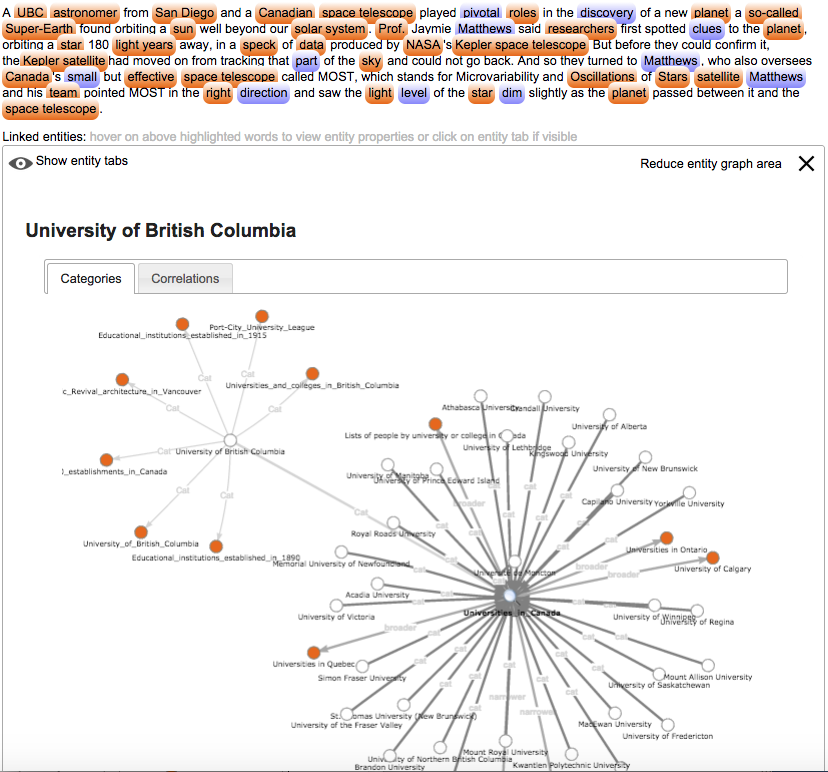
Figure 2 – Related Entities in Knowledge Graph are reachable with one click
The way entities are discovered relies on the RDF model with which DBPedia organized its entities, thus working with the ID of an entity rather than with its labels. DBPedia names every entity with an expressive ID like „http://dbpedia.org/page/Light-emitting_diode“ where “Light-emitting_diode” is the ID of the same DBPedia entity with label “Light-emitting diode”. This approach is faster in accessing entities, since a direct match is tried and on success the entity is taken.
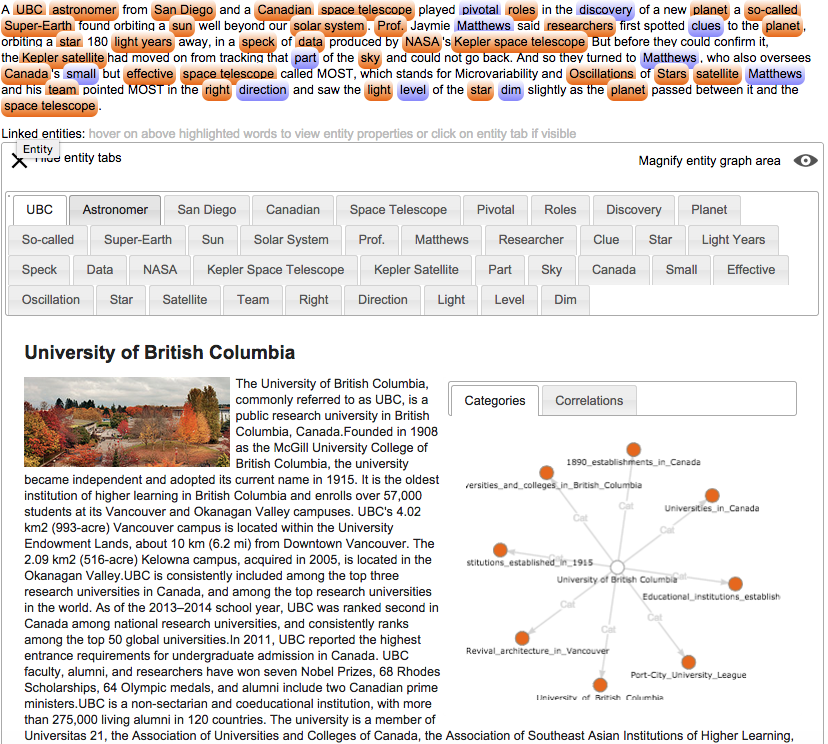
Figure 3 – linked entities ant their descriptions
Entity Linking is de facto an important contribution to information processing in natural language texts, where additional detailing information is gathered ad reading time and persons are supported in getting further details on the read text. Once entities are linked, their connections inside the knowledge graph allow for a rapid exploration of related information. Major efforts should be put in disambiguation techniques in order to understand terms intentionally used with irony or as metaphors, using systems like /LINGUEE/ with large sets of text cases to evaluate and rank possible interpretations in case of ambiguity. In 2007 Entity linking has been suggested as a way to automate the construction of a semantic web /wikify07/. It is my personal opinion that Entity Linking is a necessary step to creation of a basis for machine understangding.
Last not least, Business intelligence seems to be one of the branches which could take great advantage from Entity Linking: information on written resources can be automatically taken as a basis for comparing/calculating competition and potentials on new or changed objects (person descriptions, companies, and so forth) provided, this piece of information is already in the knowledge graph.
| /DBP2014/ | DBPedia 2014 – http://www.dataversity.net/dbpedia-2014-announced |
| /ELd2015/ | Entity Linker Demonstrator – http://semweb.ch/leistungen/rdfservices/en-entitylinking |
| /Boas2015/ | Blog on Ontology Assisted Search – http://semweb.ch/en-blog/en-blog201503challengesinsemanticsearch |
| /LINGUEE/ | http://www.linguee.de |
| /RDF/ | Resource Description Framework: http://www.w3.org/RDF |
| /SKOS/ | Simple Knowledge Organization System – http://en.wikipedia.org/wiki/Simple_Knowledge_Organization_System |
| /Watson11/ | IBM Watson – http://en.wikipedia.org/wiki/Watson_%28computer%29 |
| /wikify07/ | Rada Mihalcea and Andras Csomai (2007). Wikify! Linking Documents to Encyclopedic Knowledge. Proc. CIKM. |